Efficient Ticket Management Using LangChain and Large Language Models
LangChain agents, powered by ChatGPT, revolutionize JIRA ticket creation for seamless cross-team collaboration, boosting efficiency and productivity.
Join the DZone community and get the full member experience.
Join For FreeIn today's dynamic business landscape, where retailers, banks, and consumer-facing applications strive for excellence and efficiency in customer support, the reliance on tools like JIRA for project management remains paramount. However, the manual creation of tickets often results in incomplete information, leading to confusion and unnecessary rework, particularly in sectors where live chatbots play a crucial role in providing real-time support to end-users.
In this article, we'll explore how AI chatbots, powered by large language models, can streamline manual ticket creation. With artificial intelligence in play, businesses can reshape their project management strategies and deliver flawless customer support experiences.
Solution
The proposed solution will leverage ChatGPT, a large language model from OpenAI. We are going to leverage LangChain, an open-source library to facilitate the smooth integration with OpenAI. Please note that you can also leverage Llama2 models with LangChain for this use case.
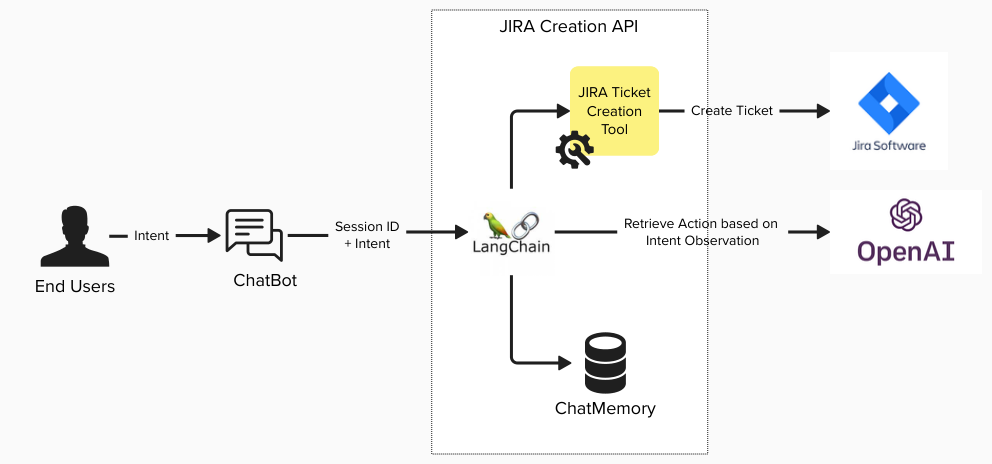
Figure 1: Leveraging LLM-enabled chatbot
The solution components include:
- LangChain agents: The fundamental concept behind agents involves using a language model to decide on a sequence of actions. Unlike chains, where actions are hardcoded into the code, agents utilize a language model as a reasoning engine to ascertain which actions to execute and in what sequence.
- Tools: When constructing the agent, we will need to provide it with a list of tools that it can use. We will create a custom tool for Jira API.
- Chat memory: LangChain agents are stateless they don't remember anything about previous interactions. Since we want the AI model to collect all the relevant information from the user before creating the JIRA ticket we need the model to remember what the user provided in the previous conversation.
Installing LangChain
Let's first install all the dependencies:
pip install langchain-openai langchain atlassian-python-api -ULet's set the environment variables:
import os
os.environ["JIRA_API_TOKEN"] = "<jira_api_token>"
os.environ["JIRA_USERNAME"] = "<jira_username>"
os.environ["JIRA_INSTANCE_URL"] = "<jira_instance_url>"
os.environ["OPENAI_API_KEY"]= "<open_api_key>"Now, let's initialize the model. For this article, we will leverage OpenAI models.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="model-name", temperature=0)
Creating Tools
We will define the input schema using the Pydantic Python library. Pydantic is a data validation and settings management library in Python that is widely used for defining data models. Pydantic guarantees that input data conforms to specified models, thereby averting errors and discrepancies. It aids in generating documentation from field descriptions, thereby enhancing comprehension of data structures.
Let's take a look at the schema defined using the Pydantic Python library:
from langchain.pydantic_v1 import BaseModel, Field
from typing import List, Optional, Type
class TicketInputSchema(BaseModel):
summary: str = Field(description="Summary of the ticket")
project: str = Field(description="project name", enum=["KAN","ABC"])
description: str = Field(description="It is the description of the work performed under this ticket.")
issuetype: str = Field(description="The issue type of the ticket ", enum=["Task", "Epic"])
priority: Optional(str) = Field(description="The issue type of the ticket ", enum=["Urgent", "Highest","High", "Low", "Lowest"])
Based on the code summary above, project, description, and issue type are required while priority is optional.
This @tool decorator is the simplest way to define a custom tool. The decorator uses the function name as the tool name by default, but this can be overridden by passing "ticketcreation-tool" as our tool name. We will pass the args_schema as TicketInputSchema as defined above using Pydantic. This will force the language model to first ensure the schema is validated before proceeding with tool invocation. Additionally, we will include a docstring to help the language model understand the purpose of this tool and the expected output structure.
We will leverage JiraAPIWrapper provided by LangChain, which is a class that extends BaseModel and is a wrapper around atlassian-python-api. The atlassian-python-api library provides a simple and convenient way to interact with Atlassian products using Python.
from langchain.utilities.jira import JiraAPIWrapperLet's look at the complete code:
@tool("ticketcreation-tool", args_schema=TicketInputSchema)
def ticketcreation(
summary: str,
project: str,
description: str,
issuetype: str,
priority: str) -> dict:
""" This tool is used to create a jira issue and returns issue id, key, links"""
import json
payload = json.dumps({
"project": {
"key": project
},
"summary": summary,
"description": description
"issuetype": {
"name" : "Task"
},
"priority": {
"name": priority
},
# "custom_field_10010":{
# "value": impact
# }
})
response = JiraAPIWrapper().issue_create(payload)
return response
We will use the code below to bind the tools with the model:
tools = [ticketcreation]
llm_with_tools = llm.bind(tools)Memory Management
This solution will leverage ConversationBufferMemory.
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="history", return_messages=True)Defining the Prompt
In a LangChain OpenAI prompt, system messages offer context and instructions, followed by placeholders for user input and agent scratchpad.
The system message component in the prompt lets the model know the context and provides guidance. Here is a sample system message that I have used:
(
"system",
"""
You are skilled chatbot that can help users raise Jira tickets.
Ask for the missing values.
Only Allow values from allowed enum values
""",
)Our input variables will be limited to input, agent_scratchpad, and history.
inputwill be provided by the user during invocation, containing instructions for the model.agent_scratchpadwill encompass a sequence of messages containing previous agent tool invocations and their corresponding outputs.historywill hold interaction history and generated output.
Here is a sample history object:
[HumanMessage(content='Can you help me create a jira ticket'), AIMessage(content='Sure, I can help with that. Please provide me with the details for the Jira ticket you would like to create.')], 'output': 'Sure, I can help with that. Please provide me with the details for the Jira ticket you would like to create.'}
And here is the prompt code using ChatPromptTemplate:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""
You are skilled chatbot that can help users raise jira tickets.
Ask for the missing values.
Only Allow values from allowed enum values.
"""
),
MessagesPlaceholder(variable_name="history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
Agent Pipeline
This pipeline represents the sequence of operations that the data goes through within the agent. The pipeline below is defined using the pipeline operator "|" which ensures that the steps are executed sequentially.
from langchain.agents.format_scratchpad.openai_tools import format_to_openai_tool_messages
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
"history": lambda x: x["history"],
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)The purpose of the "OpenAIToolsAgentOutputParser()" component in the pipeline is to parse and process the output generated by the agent during interaction.
Agent Executor
The agent executor serves as the core engine for an agent, managing its operation by initiating activities, executing assigned tasks, and reporting outcomes. The following code demonstrates the instantiation of AgentExecutor.
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=mytools, verbose=True, memory=memory, max_iterations=3)Session Management
To manage sessions when executing the tool, we will use ChatMessageHistory, a wrapper that offers easy-to-use functions for storing and retrieving various types of messages, including HumanMessages, AIMessages, and other chat messages.
The RunnableWithMessageHistory encapsulates another runnable and oversees its chat message history. It's responsible for both reading and updating the chat message history.
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="history",
)By default, the encapsulated runnable expects a single configuration parameter named "session_id," which should be a string. This parameter is utilized to either create a new chat message history or retrieve an existing one.
agent_with_chat_history.invoke(
{"input": message},
config={"configurable": {"session_id": conversation_id}},
)Conclusion
Integrating AI chatbots driven by large language models offers businesses a significant chance to enhance internal operations, streamlining project management and customer support. However, security and hallucination concerns may hinder immediate adoption by external consumers. Careful consideration of these factors is essential before implementing AI chatbots for customer-facing purposes.
Opinions expressed by DZone contributors are their own.
Comments