Understanding Gen AI: RAG Implementation
RAG is a technique to use existing LLMs to generate contextual responses with proprietary data, without the need to retrain the LLMs, offering a cost-effective solution.
Join the DZone community and get the full member experience.
Join For FreeIn the era of artificial intelligence, Natural Language Processing (NLP) has advanced significantly leading to the development of multiple Large Language Models (LLMs) capable of understanding and generating text, thereby enabling human-like responses. These LLMs are trained on a vast volume of information available on the open internet. However, if the models are expected to process and provide details on proprietary data, they will fail since they have not been trained on that specific data.
Retrieval-augmented generation is an effective technique that can be applied to leverage LLMs for providing valid responses to user queries based on proprietary data without the need to train them on that data explicitly. This article attempts to identify the steps and components involved in the successful implementation of RAG for LLM.
Understanding GenAI and LLM
Generative AI (GenAI) refers to the concept of AI models that can generate new content, including text, images, or even music, based on patterns learned from vast datasets. The primary focus of Large Language Models (LLM) is on language modeling. These models are trained on vast amounts of text data. Because of this, the LLMs can predict precisely what comes next in each sequence of words or provide a valid response based on the prompt. Leveraging Generative AI in the domain of Natural Language Processing has led to the development of Large Language Models (LLM), such as GPT (Generative Pre-trained Transformer) models. These models have significantly advanced the capabilities of machines to understand and generate human-like text.
Utilizing LLM in Any Industry
LLMs can be used across different industries such as healthcare, finance, customer service, education, etc. It can also be leveraged to efficiently summarize, recognize, predict, translate, and generate text and other forms of content as well based on the knowledge gained from massive datasets on which they are trained. By integrating LLMs into workflows, repetitive tasks can be automated, personalized recommendations can be generated, and real-time insights can be gathered.
LLM With Enterprise-Specific Data
When it comes to implementing LLMs, enterprises have three different options. They can use 1) an existing LLM without training, 2) fine-tune/retrain LLM with proprietary data, and 3) build a custom LLM from scratch. The first option of using an existing LLM is a quick and economical solution, but the LLMs won’t be able to provide details about proprietary information. With the second approach of fine-tuning LLM, organizations can tune the model for enterprise-specific tasks and proprietary knowledge. The third option of building an LLM from scratch provides the highest flexibility but it is a time-consuming and expensive approach. So, most enterprises leverage the first approach of using an existing LLM and build context using the proprietary data. One such implementation technique is the RAG – Retrieval-Augmented Generation approach.
What Is RAG?
Retrieval-Augmented Generation (RAG) is an innovative architecture that combines the strengths of foundational LLM models like Llama 2, ChatGPT, Claude, etc., and the enterprise-specific proprietary information without the need to retrain the LLMs on this proprietary data. It seamlessly integrates pre-trained retrieval models with generative language models to retrieve and generate responses based on relevant context from large-scale knowledge sources.
Embedding
Before diving into RAG, it is crucial to understand what is embedding. Embeddings are numerical representations of text, in multi-dimensional space. Embeddings that are numerically similar will also be semantically similar and will be represented closer to the vector space. Embedding models are a type of language model, which can encapsulate information in a multi-dimensional vector space. In short, the embedding model converts the input information and converts them into a vector representation. 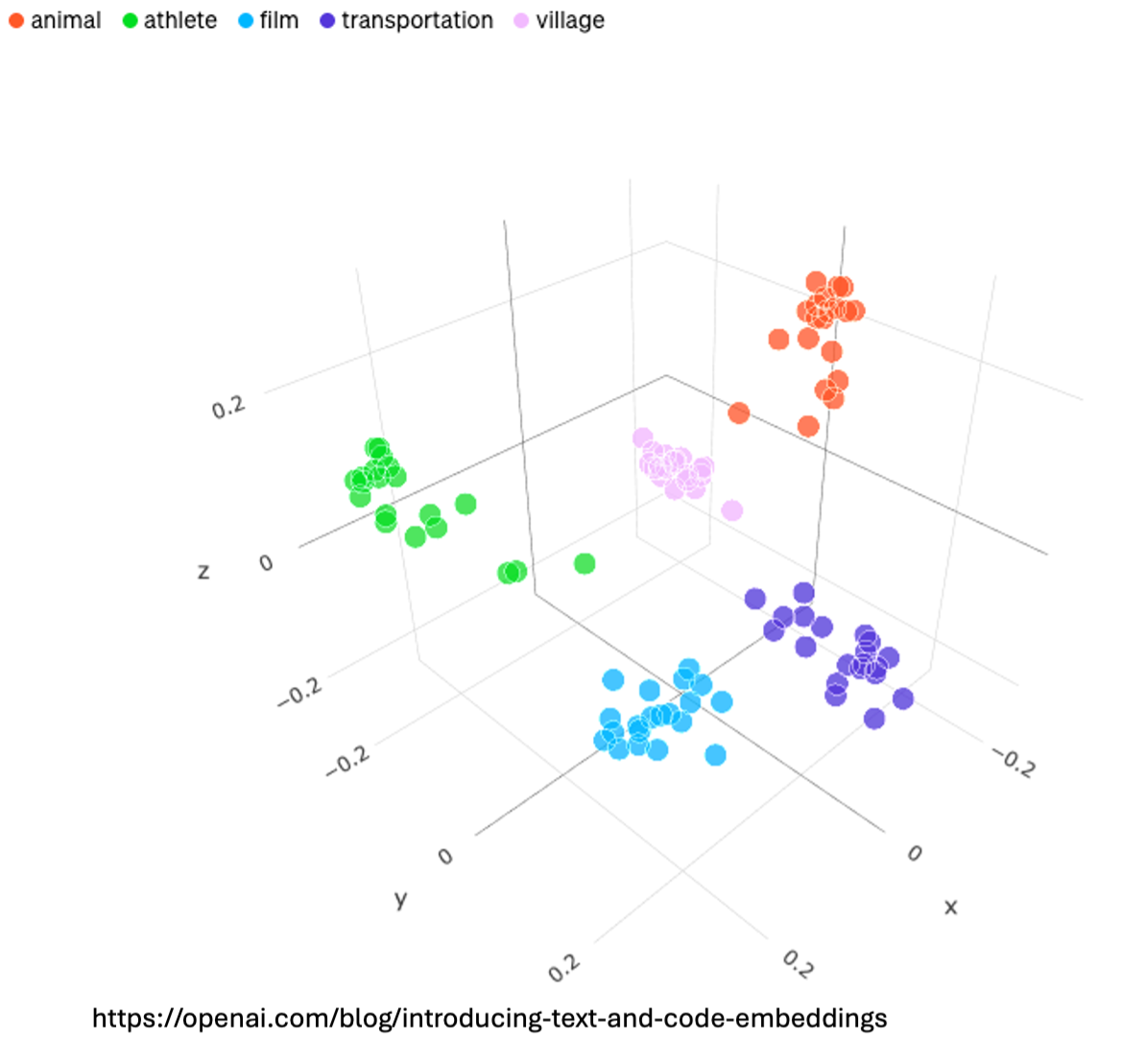
Embedding Types
In the context of RAG LLMs, there are multiple different types of embeddings that exist. The most common are word embeddings like Word2Vec, and GloVe, and sentence embeddings ELMo, InferSent, and SBERT embeddings. Each of these embedding types has unique characteristics. For instance, the embedding type Word2Vec is a type of predictive embedding that either predicts the words for the context or predicts the context for given words. GloVe captures semantic relationships based on word co-occurrences. Whereas SBERT embeddings, are contextually richer, capturing the nuances of word meanings based on surrounding text.
Chunking Algorithms
The proprietary documents should be broken down into semantically cohesive chunks, which is pivotal in RAG LLMs. This process is called chunking. The chunking algorithm significantly influences the granularity and relevance of the information retrieved.
Chunking in Vector Databases vs. Regular Search
The key difference between Chunking in a vector database and a regular search is that, in chunking the documents are segmented into chunks or portions which are semantically cohesive, thereby ensuring a complete idea or a concept is encapsulated within each chunk. Whereas in a regular text search, the focus is more on the keywords and specific text fragments.
Components of RAG Architecture
The RAG architecture comprises several key components, including a generative language model for response generation, embedding models for representing documents and queries, vector databases for efficient retrieval, and integration with LLMs for language understanding and generation.
RAG Implementation
RAG consists of three phases. 1) Ingestion of document repositories, and databases, that contain proprietary data. 2) Retrieval of relevant data based on user query 3) Generation of response to the user
Ingestion Phase
Before the LLM can reference and use any proprietary data, the proprietary data must be prepared to consumable format. This process is called the ingestion. The first step in the ingestion phase is to read the data which could be Markdowns, PDFs, Word documents, PowerPoint decks, images, audio and video, etc.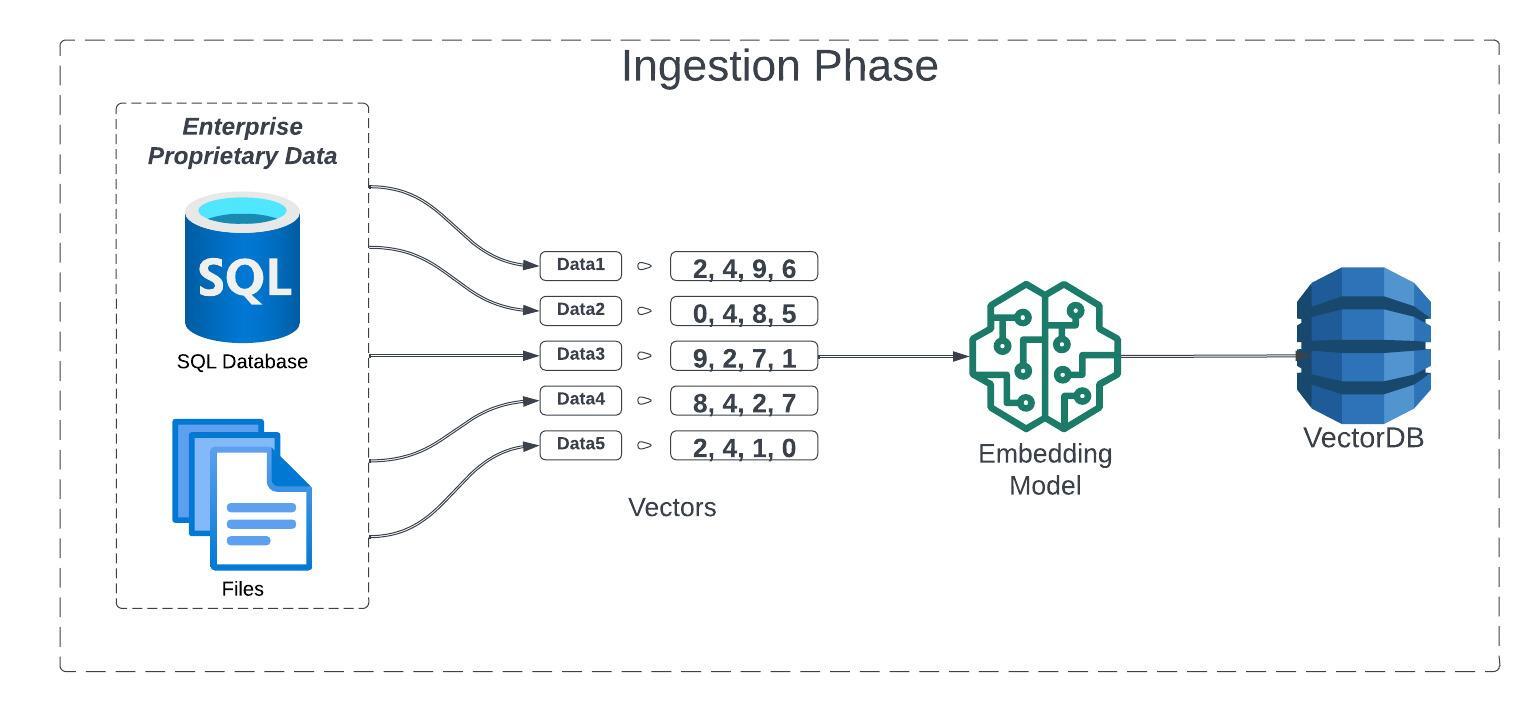
Once the data is read, it should be transformed by chunking, extracting metadata, and embedding each chunk. These chunks are passed on to an embedding model which converts the content to vectors (or embeddings). The final embedding is a numerical representation of the semantics or meaning of the text. The pieces of text which have similar meanings will also have mathematically similar embeddings. These embeddings are then loaded into a vector database.
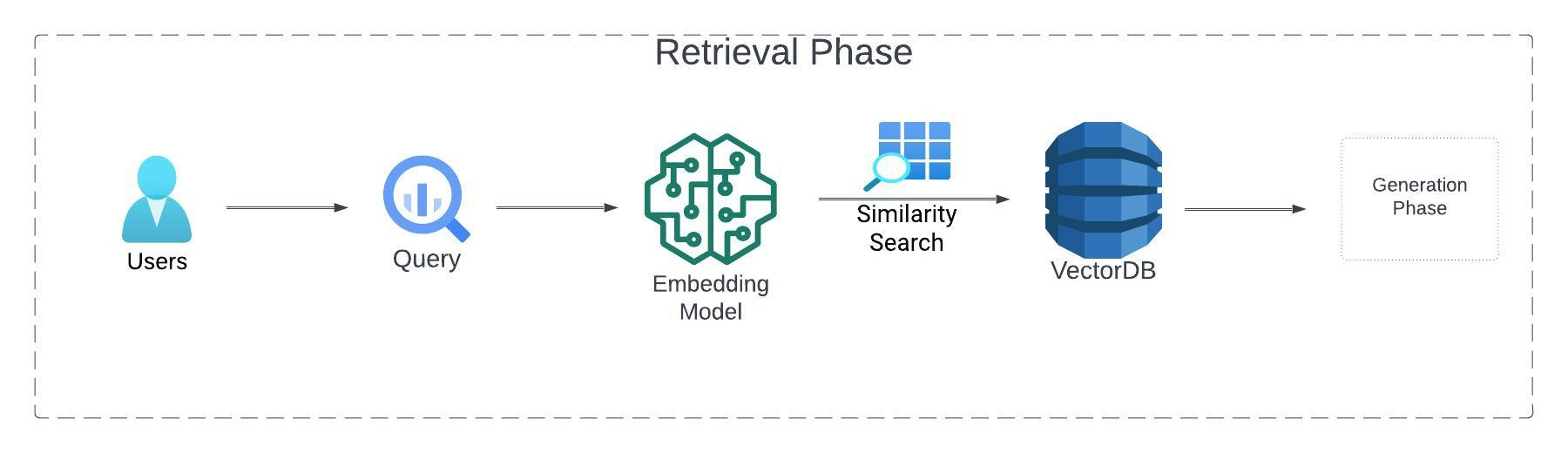
Retrieval Phase
Once all the proprietary data is stored as embeddings in the vector database, the next phase would be retrieval. In this phase, the user query is converted into embeddings using the same approach mentioned in the ingestion phase. The embeddings of the user query are used on the vector database and the information most relevant to the user query is extracted from the vector database. In short, based on the user query, any proprietary data that is most relevant to the query is extracted from a store of semantic search vectors by using a similarity search.
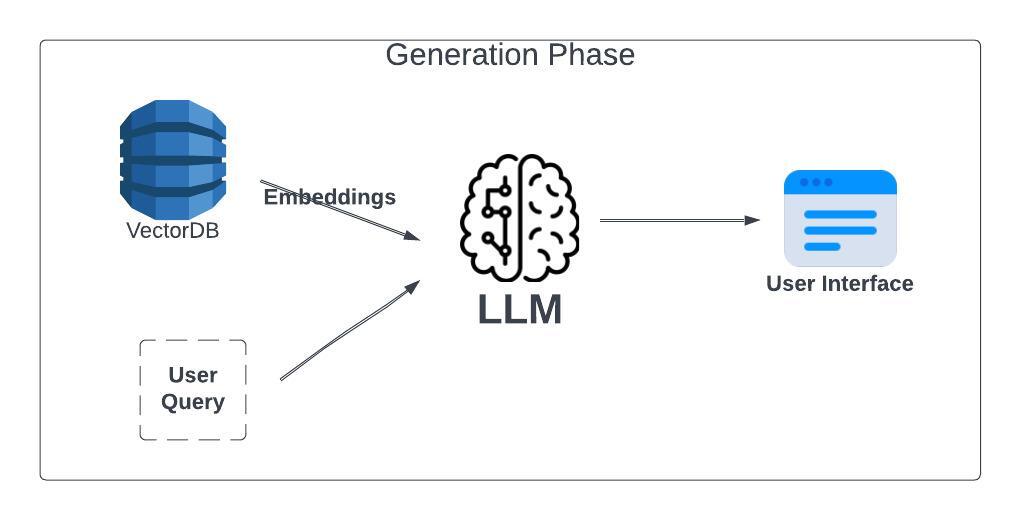
Generation Phase
Once the embeddings relevant to the user query are retrieved from the vector db, it is passed along with the user query as context for the LLM. This context forms the basis for the LLM to interpret the user query and understand the related proprietary data passed as embeddings. Finally, the LLM combines the embeddings and the user query to generate a final answer which is sent back to the user as a response.
Choosing the Right Components for RAG
Embedding Models
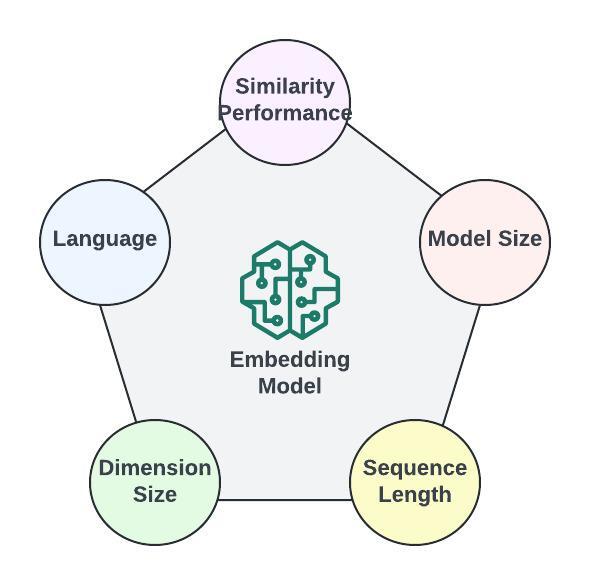
Choosing the right embedding model is key for the relevance and usability of the RAG implementation. The embedding model can be decided on different factors such as
- Similarity performance: How well embeddings match based on MTEB — Mean Task Embedding Benchmark score.
- Model size: It attributes the operational cost of storing and loading the model into memory.
- Sequence length: This is the number of input tokens a model supports. This is a crucial factor.
- Dimension size: Embeddings based on their dimension size will be effective in capturing complex relationships in data if it is large, but add more operational cost, whereas a small dimension size would be cost-effective but could impact the models’ ability.
- Language: This factor also determines the model as most smaller models support only English Language). Various embedding models, such as BERT (Bidirectional Encoder Representations from Transformers), RoBERTa (Robustly Optimized BERT Approach), or SBERT (Sentence-BERT), can be utilized to encode documents and queries into dense vector representations for efficient retrieval.
Vector Databases
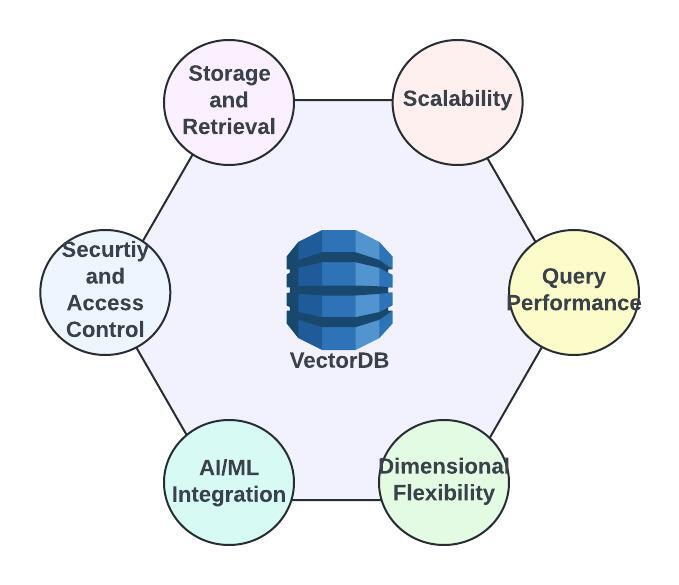
Vector databases, like embedding models, play a crucial role in successful RAG implementation. Some of the leading vector databases available are PGVector (open-source), Milvus (open-source), Pinecone, Weaviate (open-source), Elasticsearch, and Vespa. The key factors to consider in deciding a vector database are
- Storage and retrieval efficiency: Vector databases should excel in efficiently storing and retrieving vectors thereby ensuring optimal performance for faster retrieval and response generation.
- Scalability: A critical factor of vector databases is their ability to scale. As the volume of proprietary data, documents, and other material grows, the vector database should be capable of scaling without performance impact.
- Query performance: The right vector databases should optimize query speed and excel in swiftly accessing and processing vector information.
- Dimensional flexibility: Based on the vector embeddings need, the vector databases should have dimensional flexibility to accommodate several dimensions from tens to thousands. However, in RAG use cases, consistency should be maintained by keeping dimensionality fixed.
- Integration with AI and ML frameworks: If the vector databases can seamlessly integrate with popular AI and ML frameworks, then it simplifies the deployment and utilization of vector data. Thereby the vector database capable of integrating with AI/ML frameworks should be identified.
- Security and access control: As proprietary data is stored in a vector database as part of the ingestion phase, it should be equipped with robust security features to safeguard critical and sensitive information.
![VectorDB]() Large Language Model
Large Language Model
 Large Language Model
Large Language ModelLLM being the heart of generative AI implementation, choosing the right LLM is crucial for success. Cost is the key factor to consider when choosing the LLM. The cost associated with an LLM is defined by size and licensing.
- Size: When choosing an LLM, cost is determined by the size of the model. Running LLMs can be very expensive, so it is vital to choose the right model. The number of parameters of an LLM can be used as an indicator of the size of the model and thereby the cost it incurs.
- Licensing: If an LLM needs to be used for commercial purposes, then the license of a particular model should be considered. Proprietary models like GPT-3 and GPT-4 come with premium pricing as it is set up to run via simple API calls and support is available. Open-source models such as Dolly, OpenLLaMA, etc., come with a license making it feasible for cost-effective commercial purposes.
Advantages of RAG
- Cost-effective implementation: Implementing generative AI for business use cases using an LLM model will be expensive if the model must be built from scratch. On the contrary, the cost associated with the computation of retraining foundation models on proprietary data is still significantly high. RAG architecture provides a cost-effective approach to implement generative AI, without the need to spend a huge amount, by incorporating the proprietary data to the existing LLM model.
- Current information: The LLMs need to be updated regularly to stay current date. With RAG it is easy for the developers to build the context to the LLM using the latest research, statistics, or news, thereby eliminating the need to update the model.
- Enhanced user trust: RAG allows the LLM to present the output with citations and references. This enables the users to look up source documents themselves to validate and can get further clarification or more detail if required from the original source, making the RAG approach trustable for generative AI solutions.
- More developer control: The testing and optimization of the application is more efficient with RAG. Developers can control and change the LLM's source or proprietary data to adapt to changing requirements or cross-functional usage. Sensitive information retrieval can also be restricted to different authorization levels and ensure the LLM generates appropriate responses.
Conclusion
The implementation of Retrieval-Augmented Generation (RAG) represents a significant advancement in leveraging Large Language Models (LLMs) for incorporating proprietary data without the need for extensive retraining of the models. By seamlessly integrating pre-trained retrieval models with generative language models, RAG enables organizations to harness the power of LLMs while accessing enterprise-specific knowledge. By incorporating proprietary data into existing LLM models, organizations can automate tasks, generate personalized recommendations, and gather real-time insights across various industries.
As artificial intelligence continues to evolve, RAG stands out as a valuable and cost-effective technique for bridging the gap between LLMs and enterprise-specific data, paving the way for innovative applications and solutions in the realm of natural language processing.
This article has outlined the essential components and phases involved in RAG implementation, emphasizing the importance of embedding models, and vector databases, and selecting the right LLM.
Opinions expressed by DZone contributors are their own.
Comments